
この記事の内容
Pythonでデータ解析を支援する機能を提供するライブラリとして有名な、Pandasの基本的な操作方法を紹介します。機械学習、データ分析で必要になる知識となります。基本的にデータをDataFrameオブジェクトで保持する形になり、それを扱っていきます。SQLの概念と似ていますので、SQLをご存じの方はすんなりと理解できるかと思います。
使用するファイル
本記事で使用するファイルは以下よりダウンロードできます。
Pandasの基本的な操作方法
CSVファイルのDataFrameへ読み込み
CSVファイルを読み込み、pandasのDataFrameを取得し、ヘッダ行および先頭の5行分のデータを表示します。
読み込みには、read_csv関数を使用します。先頭の5行を表示するには、head関数を使用します。
import pandas as pd
# CSVを読み込んで、pandasのDataFrameを取得
employee_data_frame = pd.read_csv('employee_01.csv')
#DataFrameの先頭5行を表示
employee_data_frame.head()
出力結果
DataFrameの行結合(Union)
DataFrame同士を行結合(Union)します。行結合には、concat関数を使用します。
import pandas as pd
employee_01_data_frame = pd.read_csv('employee_01.csv')
print(f"employee_01 records={len(employee_01_data_frame)}")
employee_02_data_frame = pd.read_csv('employee_02.csv')
print(f"employee_02 records={len(employee_02_data_frame)}")
# ignore_index = Trueを指定することで、連結方向のラベルを 0 から振りなおす
union_data_frame = pd.concat([employee_01_data_frame, employee_02_data_frame], ignore_index = True)
print(f"union_data_frame records={len(union_data_frame)}")
出力結果

DataFrameの列結合(Join)
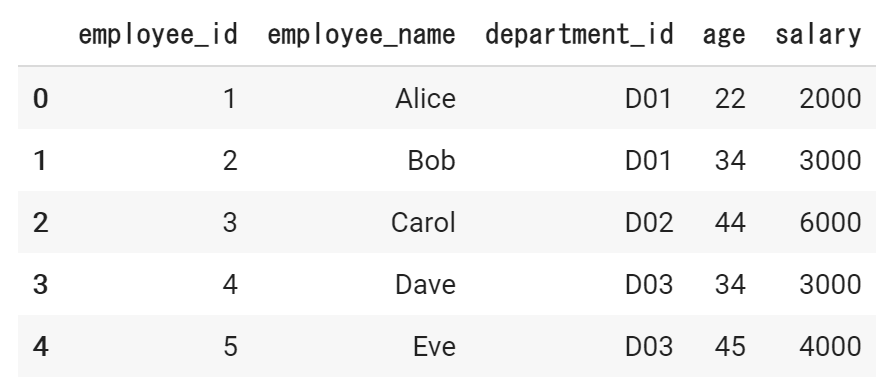
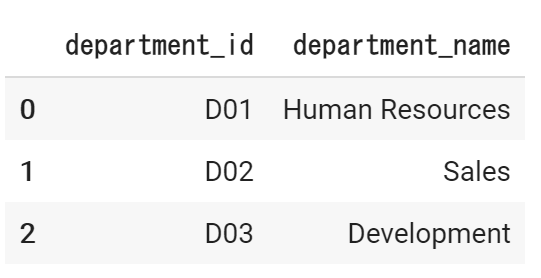
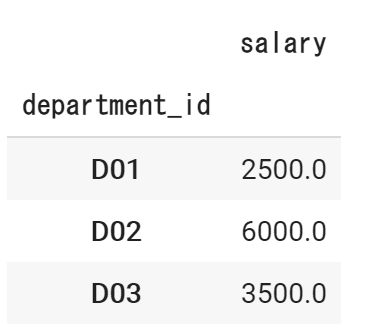
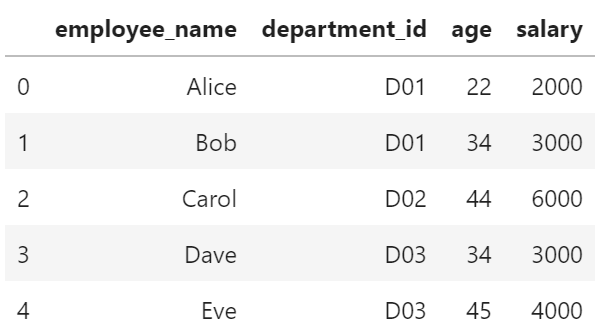
以下の、従業員テーブルと部署テーブルを、department_idをキーに、列結合します。(left join)
列結合には、merge関数を使用します。
従業員テーブル
部署テーブル
import pandas as pd
employee_data_frame = pd.read_csv('employee_01.csv')
department_data_frame = pd.read_csv('department.csv')
join_data_frame = pd.merge(employee_data_frame, department_data_frame, on="department_id", how="left")
join_data_frame.head()
出力結果

DataFrameへの列追加
以下の従業員テーブルのsalaryをもとに、bonus列を追加します。bonusの値は、salaryの2倍(2か月分)とします。
import pandas as pd
employee_data_frame = pd.read_csv('employee_01.csv')
employee_data_frame["bounus"] = employee_data_frame["salary"] * 2
employee_data_frame.head()
出力結果
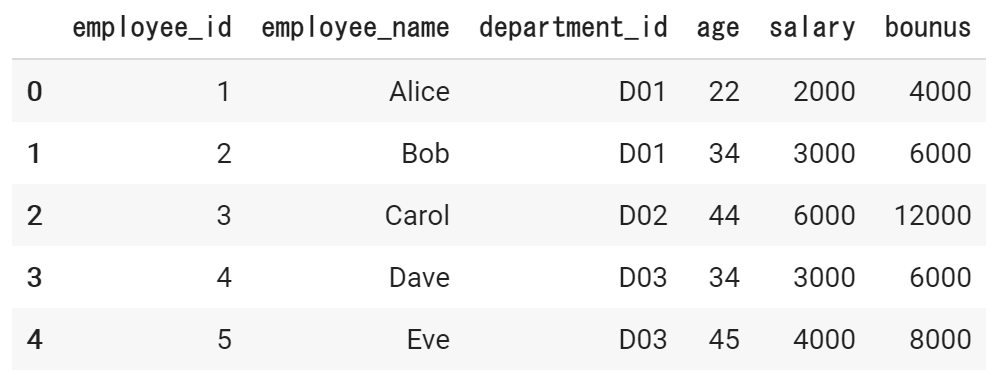
最大値、最小値、平均値、合計値の算出
以下の従業員テーブルのsalary列を使用して、最大値(max)、最小値(min)、平均値(mean)および合計値(sum)を求めます。
import pandas as pd
employee_data_frame = pd.read_csv('employee_01.csv')
# 最大
max_salary = employee_data_frame["salary"].max()
print(f"max_salary={max_salary}")
# 最小
min_salary = employee_data_frame["salary"].min()
print(f"min_salary={min_salary}")
# 平均
mean_salary = employee_data_frame["salary"].mean()
print(f"mean_salary={mean_salary}")
# 合計
sum_salary = employee_data_frame["salary"].sum()
print(f"sum_salary={sum_salary}")
出力結果

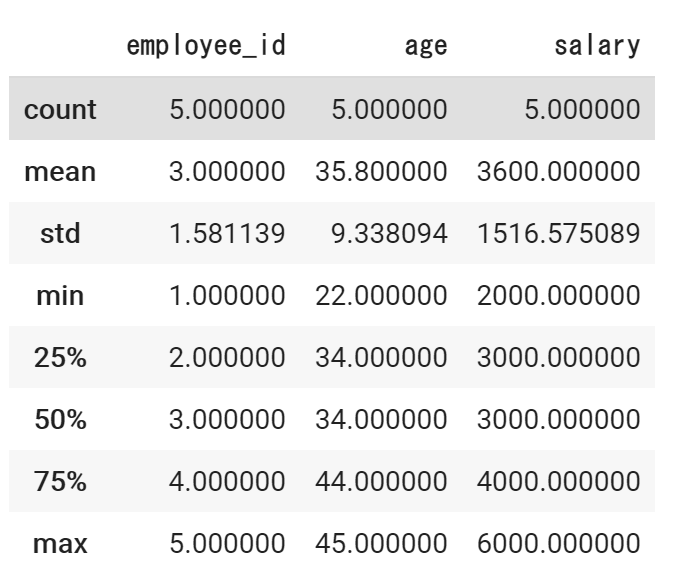
統計情報の算出
各種統計情報を算出します。(カウント、平均値、標準偏差、最小値、最大値など)
統計情報の算出には、describe関数を使用します。
import pandas as pd
employee_data_frame = pd.read_csv('employee_01.csv')
employee_data_frame.describe()
出力結果
DataFrameの列型確認
DataFrameの各列のデータ型を確認します。
データ型の確認にはdtypesプロパティより取得します。
import pandas as pd
employee_data_frame = pd.read_csv('employee_01.csv')
employee_data_frame.dtypes
出力結果

グループ化しての集計
部署ごとに、平均給与を集計します。
グループ化しての集計は、groupby関数を使用します。
import pandas as pd
employee_data_frame = pd.read_csv('employee_01.csv')
employee_data_frame.groupby(["department_id"]).mean()[["salary"]]
出力結果
列を指定して、一意なデータを取得する
従業員表から、部署IDをもとに一意(ユニーク)になるデータを取得して表示します。
一意となる値の取得には、unique関数を使用します。
import pandas as pd
employee_data_frame = pd.read_csv('employee_01.csv')
print(pd.unique(employee_data_frame.department_id))
出力結果
![]()
不要な列を削除する
drop関数を使用します。また、引数のcolumnsに削除対象の列名をリストで指定します。
import pandas as pd
employee_01_data_frame = pd.read_csv('employee_01.csv')
employee_01_data_frame = employee_01_data_frame.drop(columns = ['employee_id'])
employee_01_data_frame.head()
出力結果
DataFrameのCSVファイル保存
DataFrameを指定して、CSVファイルへ保存します。
CSVファイルの保存は、to_csv関数を使用します。
import pandas as pd
employee_data_frame = pd.read_csv('employee_01.csv')
employee_data_frame["bounus"] = employee_data_frame["salary"] * 2
employee_data_frame.to_csv("dump_data.csv", index=False)
Excelファイルの読み込み
Excelファイル(xlsx形式)を読み込みます。読み込みには、read_excel関数を使用します。
import pandas as pd
employee_data_frame = pd.read_excel("employee.xlsx")
employee_data_frame.head()
出力結果

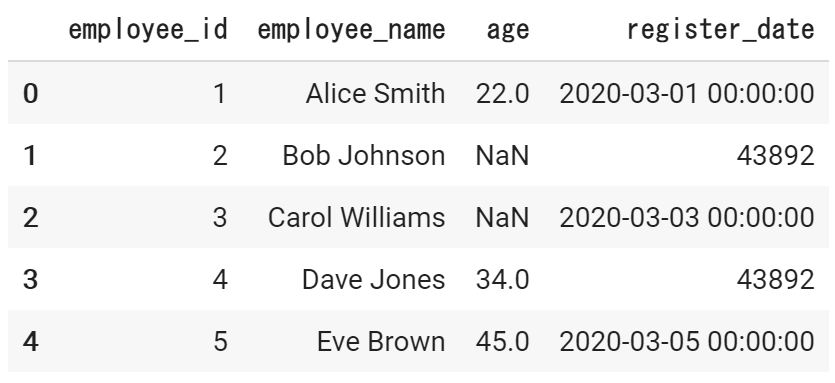
文字列表記の揺れ修正
以下の、employee_nameのスペースで大文字と小文字が混じっているため、半角に統一します。そのため、全角のスペースを半角のスペースに置換する処理を行います。
import pandas as pd
employee_data_frame = pd.read_excel("employee.xlsx")
employee_data_frame["employee_name"] = employee_data_frame["employee_name"].str.replace(" "," ")
employee_data_frame.head()
出力結果
欠損値の有無確認
以下の表では、age列に一部データが入っていない箇所があります。このようなデータが入っていないか確認するための方法を示します。
import pandas as pd
employee_data_frame = pd.read_excel("employee.xlsx")
employee_data_frame.isnull().any(axis=0)
出力結果

欠損値の数を集計
DataFrame.isnull().sum()で各列ごとの欠損値の数を集計します。
import pandas as pd
employee_data_frame = pd.read_excel("employee.xlsx")
employee_data_frame.isnull().sum()
出力結果

欠損値が1つでも含まれている列がある場合、その行を削除する
import pandas as pd
employee_data_frame = pd.read_excel("employee.xlsx")
dropped_frame = employee_data_frame.dropna()
print(dropped_frame.head())
出力結果

欠損値部分を特定の値で埋める
欠損値部分をDataFrame.fillna([埋める数])で補完することができます。
import pandas as pd
employee_data_frame = pd.read_excel("employee.xlsx")
filled_frame = employee_data_frame.fillna(0)
print(filled_frame.head())
出力結果

さいごに
この記事では、基本的なPandasの操作方法について紹介しました。
より実践的な機械学習等の内容については後日公開予定です。


コメント